Building an AI Agent with Long-Term Memory Using Vector Database

Building an AI Agent with Long-Term Memory Using Vector Database
This tutorial shows how to implement an agent with long-term memory capabilities using LangGraph. The agent can store, retrieve, and use memories to enhance its interactions with users.
We’ll build a terminal-based chatbot that remembers important details using a vector database (FAISS) for persistent memory. The agent uses LangGraph, Gemini (via LangChain), and Google embeddings to manage conversations across sessions.
Why Long-Term Memory?
Typical LLM agents are stateless. That means they forget what the user said the last time. To simulate memory, we can persist selected memories in a vector database and retrieve them contextually in the next conversation.
This way, when you tell the AI your name today, it’ll remember it tomorrow.
Setting Up the Project
Install the required dependencies:
pip install langchain langgraph langchain-community langchain-google-genai faiss-cpu python-dotenvWe’ll need an API key from Google AI Studio. It’s free to sign up and lets us use LLMs like Gemini.
Create a .env file:
GOOGLE_API_KEY=your_google_api_key📦 Required Imports
Before we begin, make sure to include the following imports. These cover everything from environment setup and embeddings to LangGraph nodes and memory management:
import os
import uuid
from typing import List
from dotenv import load_dotenv
from langchain_google_genai import ChatGoogleGenerativeAI, GoogleGenerativeAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_core.documents import Document
from langchain_core.messages import get_buffer_string
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableConfig
from langchain_core.tools import tool
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import END, START, MessagesState, StateGraph
from langgraph.prebuilt import ToolNode
load_dotenv()
GOOGLE_API_KEY = os.getenv("GOOGLE_API_KEY")
1. Initializing the LLM and Embeddings
We use Gemini (via langchain_google_genai) and Google’s embedding model.
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash")
embeddings = GoogleGenerativeAIEmbeddings(model="models/gemini-embedding-exp-03-07")These two components are key: the LLM handles the responses, and the embedding model helps convert memory text into vectors for storage/retrieval.
2. Setting Up FAISS for Persistent Memory
We use FAISS to store memory vectors locally on disk.
FAISS_INDEX_PATH = "faiss_index"
if os.path.exists(FAISS_INDEX_PATH):
vector_store = FAISS.load_local(FAISS_INDEX_PATH, embeddings, allow_dangerous_deserialization=True)
else:
vector_store = FAISS.from_texts(["init"], embeddings) # avoid creating empty index💡 We need at least one document to create the FAISS index initially. Later, this gets overwritten.
3. Creating Tools to Save and Search Memory
We create two tools:
save_recall_memory: to save important text as memorysearch_recall_memories: to find past relevant memories
These tools rely on the user_id for scoped memory.
@tool
def save_recall_memory(memory: str, config: RunnableConfig) -> str:
"""
Save a memory string to the vector store for future semantic retrieval.
Args:
memory (str): The piece of information the agent wants to remember.
config (RunnableConfig): Runtime configuration including user_id.
Returns:
str: The same memory string that was saved.
"""
user_id = config["configurable"].get("user_id")
doc = Document(page_content=memory, metadata={"user_id": user_id})
vector_store.add_documents([doc])
vector_store.save_local(FAISS_INDEX_PATH)
return memory
@tool
def search_recall_memories(query: str, config: RunnableConfig) -> List[str]:
"""
Perform a semantic search in the vector store to retrieve relevant user memories.
Args:
query (str): The current conversation context or query to search against.
config (RunnableConfig): Runtime configuration including user_id.
Returns:
List[str]: A list of memory strings most relevant to the current query.
"""
user_id = config["configurable"].get("user_id")
results = vector_store.similarity_search(query, k=10)
filtered = [
doc.page_content for doc in results
if doc.metadata.get("user_id") == user_id
]
return filtered[:3]Note: We need to provide a docstring for functions defined using @tool. This is required by LangChain to generate the tool’s description.
❓ Common Question: “What does the agent decide to remember?”
That depends on the model. When the prompt tells the model it has a memory-saving tool, it decides what to save via tool calls.
4. Writing the Prompt
We use a detailed prompt that instructs the agent how to behave:
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant with advanced long-term memory"
" capabilities. Powered by a stateless LLM, you must rely on"
" external memory to store information between conversations."
" Utilize the available memory tools to store and retrieve"
" important details that will help you better attend to the user's"
" needs and understand their context.\n\n"
"Memory Usage Guidelines:\n"
"1. Actively use memory tools (save_core_memory, save_recall_memory)"
" to build a comprehensive understanding of the user.\n"
"2. Make informed suppositions and extrapolations based on stored"
" memories.\n"
"3. Regularly reflect on past interactions to identify patterns and"
" preferences of the user.\n"
"4. Update your mental model of the user with each new piece of"
" information.\n"
"5. Cross-reference new information with existing memories for"
" consistency.\n"
"6. Prioritize storing emotional context and personal values"
" alongside facts.\n"
"7. Use memory to anticipate needs and tailor responses to the"
" user's style.\n"
"8. Recognize and acknowledge changes in the user's situation or"
" perspectives over time.\n"
"9. Leverage memories to provide personalized examples and"
" analogies.\n"
"10. Recall past challenges or successes to inform current"
" problem-solving.\n\n"
"## Recall Memories\n"
"Recall memories are contextually retrieved based on the current"
" conversation:\n{recall_memories}\n\n"
"## Instructions\n"
"Engage with the user naturally, as a trusted colleague or friend."
" There's no need to explicitly mention your memory capabilities."
" Instead, seamlessly incorporate your understanding of the user"
" into your responses. Be attentive to subtle cues and underlying"
" emotions. Adapt your communication style to match the user's"
" preferences and current emotional state. Use tools to persist"
" information you want to retain in the next conversation. If you"
" do call tools, all text preceding the tool call is an internal"
" message. Respond AFTER calling the tool, once you have"
" confirmation that the tool completed successfully.\n\n",
),
("placeholder", "{messages}"),
]
)This part plays a huge role. A shallow prompt might fail to guide the model to use memory properly, which we discovered during testing. I used the prompt provided by the documentation of LangChain about a long-term memory agent.
5. Defining the LangGraph State and Nodes
We define a custom State with recall_memories added to it.
class State(MessagesState):
recall_memories: List[str]Define 3 nodes:
load_memories: retrieves memory based on current conversationagent: runs the LLM with prompttools: processes any tool calls (like saving memory)
def load_memories(state: State, config: RunnableConfig) -> State:
convo = get_buffer_string(state["messages"])
convo = convo[:2048] # truncate
recall = search_recall_memories.invoke(convo, config)
return {"recall_memories": recall}
def agent(state: State) -> State:
recall_str = "<recall_memory>\n" + "\n".join(state["recall_memories"]) + "\n</recall_memory>"
response = (prompt | llm_with_tools).invoke({
"messages": state["messages"],
"recall_memories": recall_str,
})
return {"messages": [response]}6. Assembling the Graph
We use LangGraph to wire up the steps:
builder = StateGraph(State)
builder.add_node(load_memories)
builder.add_node(agent)
builder.add_node("tools", ToolNode(tools))
builder.add_edge(START, "load_memories")
builder.add_edge("load_memories", "agent")
builder.add_conditional_edges("agent", lambda s: "tools" if s["messages"][-1].tool_calls else END, ["tools", END])
builder.add_edge("tools", "agent")
graph = builder.compile(checkpointer=MemorySaver())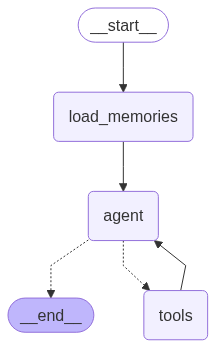
7. Terminal Chat Interface
Finally, we create a basic terminal interface.
def terminal_chat():
user_id = input("Enter your user_id: ") or "1"
config = {"configurable": {"user_id": user_id, "thread_id": str(uuid.uuid4())}}
history = []
print("\nYou can start chatting. Type 'exit' to quit.\n")
while True:
user_input = input("You: ")
if user_input.lower() in ["exit", "quit"]:
break
history.append(("user", user_input))
for chunk in graph.stream({"messages": history}, config=config):
if "agent" in chunk and "messages" in chunk["agent"]:
last_msg = chunk["agent"]["messages"][-1]
if last_msg.content:
print("AI:", last_msg.content)
history.append(("ai", last_msg.content))Final Thoughts
We’ve built a terminal-based AI assistant that remembers past interactions — a step closer to truly personalized AI experiences. Unlike typical chatbots that forget everything after a session ends, this agent recalls meaningful details, adapts over time, and grows with each conversation.
This chatbot can be further enhanced in multiple ways like:
- Expanding memory scope (e.g., per-project or per-topic)
- Logging interactions
- Running the same memory architecture in a web app
This was a great intro to combining LangGraph + LangChain + FAISS for agentic memory in a real, persistent way.